| 知乎专栏 |
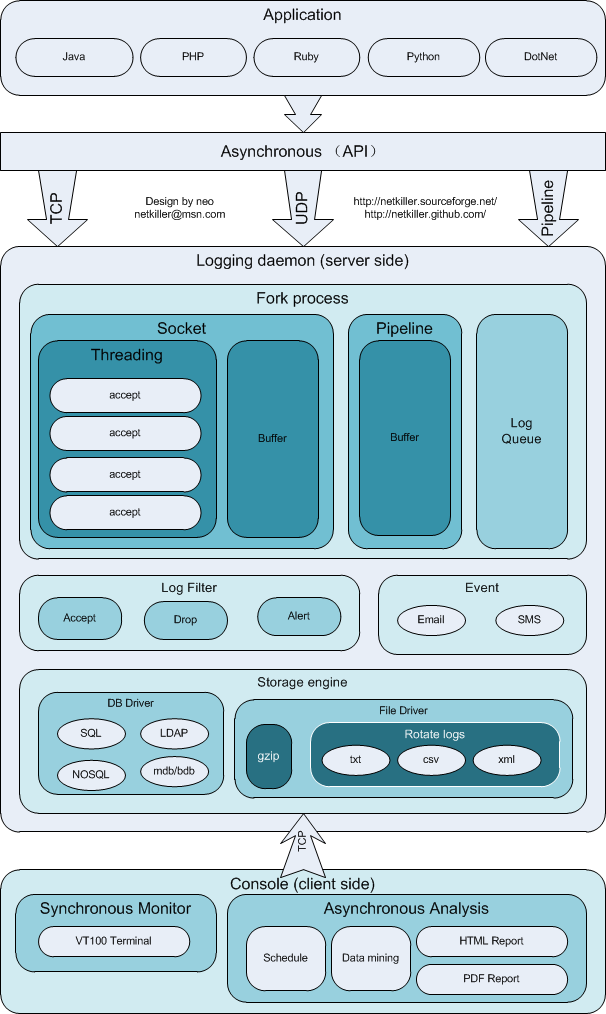 |
传统做法是文件型日志,分布在各个服务器上。在大规模部署服务器后代来很多不便,增加很多管理成本,所有我们需要集中管理服务器产生的所有日志,我们叫他日志中心服务器
很多应用程序会产生日志,有些程序已经实现了日志切割,一般是每天一个文件。但有时这个切割并不能满足我们的需求,例如我们需要颗粒度更细的切割。
切割日志的目的是什么?
切割日志基本两种方法:
日志切割方案网上有很多,很多运维也是参考这些方案进行配置,网上的例子不完全都是对的,可能你用了很多年配置方案是错误的。 没有出现故障是侥幸,因为笔者15年前就在此处栽过,由于日志太大,我便清空了日志,以为程序仍然会继续写入,最后直到服务器崩溃。 最近发现很多新手再谈cronolog,我便想起当年发生的故障,有必要跟大家分享。
首先日志是可以切割的,网上的例子理论上也是可行,但我们不能不求甚解,稀里糊涂的用下去。
我们首先了解一下日志是怎么产生的,那种日志可以切割,那些日志不能切割,为什么不能切割,如果需要切割日志怎么处理?
日志生命周期,创建/打开日志文件,追加日志记录,关闭日志文件。请看下面伪代码。
main (){
f = open(/tmp/prog.log) ...
...
f.append('DEBUG .............')
...
f.append('INFO .............')
...
f.append('WARN .............')
f.close()
}
这个程序是顺序运行,每次运行都会经历,打开日志文件,追加日志记录,关闭日志文件,一个日志生命周期结束。 在完成日志生命周后,你就可以切割日志了。因为f.close()后日志文件已经被释放。
再看下面的程序
main (){
f = open(/tmp/prog.log)
loop{
... ...
f.append('DEBUG .............')
...
f.append('INFO .............')
...
f.append('WARN .............')
if(quit){
break
}
}
f.close()
}
这个程序就不同了,程序运行,打开日志文件,然后进入无穷循环,期间不断写入日志,接到退出命令才会关闭日志。 那么这个程序你就不能随便切割日志。你一旦修改了日志文件,程序将不能在写入日志到文件中。 这个程序切割日志的过程是这样的
split loop { prog run prog quit && mv /tmp/prog.log /tmp/prog.2016-05-05.log }
再看下面的程序
main (){
loop{
f = open(/tmp/prog.log)
loop{
...
...
f.append('DEBUG .............')
...
f.append('INFO .............')
...
f.append('WARN .............')
if(reload){
break
}
}
f.close()
}
}
这个程序多了一层循环,并加入了重载功能。这个程序怎样切割日志呢:
split loop {
prog run
mv /tmp/prog.log /tmp/prog.YYYY-MM-DD.log
prog reload
}
main (){
loop{
f = open(/tmp/prog.YYYY-MM-DD.log)
loop{
...
...
f.append('DEBUG .............')
...
f.append('INFO .............')
...
f.append('WARN .............')
if(reload){
break
}
}
f.close()
}
}
如果你是程序猿,这个程序可以优化一下,日志文件名自动产生日期 /tmp/prog.YYYY-MM-DD.log 在reload时候重新创建或打开日志。
最操蛋写法,很多初学者会这么干,
log(type, msg){
f = open(/tmp/prog.YYYY-MM-DD.log)
f.append(type, msg)
f.close()
}
main(){ ...
...
log('INFO','..............') ...
...
log('DEBUG','..............') ...
...
}
这种代码的适应性非常强,写一个日志函数,但牺牲了IO性能,如果频繁打开/关闭文件同时进行写IO操作,这样的程序很难实现高并发。 所以很多高并发的程序,只会打开一次日志文件(追加模式),不会再运行期间关闭日志文件,直到进程发出退出信号。
我们手工模拟一次日志分割的过程,首先开启三个Shell终端。
终端一,模拟打开日志文件 [root@www.netkiller.cn ~]# cat > /tmp/test.log 终端二,重命名文件 [root@www.netkiller.cn ~]# mv /tmp/test.log /tmp/test.2016.05.05.log 终端一,输入一些内容然后按下Ctrl+D 保存文件 [root@www.netkiller.cn ~]# cat > /tmp/test.log Helloworld Ctrl + D[root@www.netkiller.cn ~]# cat /tmp/test.log cat: /tmp/test.log: No such file or directory
终端一,模拟打开日志文件 [root@www.netkiller.cn ~]# cat > /tmp/test.log 终端二,使用lsof查看文件的打开情况 [root@www.netkiller.cn ~]# lsof | grep /tmp/test.log cat 20032 root 1w REG 253,1 0 288466 /tmp/test.log 终端三,删除日志文件 [root@www.netkiller.cn ~]# rm -rf /tmp/test.log 终端二,查看日志的状态,你能看到 deleted [root@www.netkiller.cn ~]# lsof | grep /tmp/test.log cat 5269 root 1w REG 253,1 0 277445 /tmp/test.log (deleted) 终端一,回到终端一种,继续写入一些内容并保存,然后查看日志文件是否有日志记录被写入 [root@www.netkiller.cn ~]# cat > /tmp/test.log Helloworld ^D[root@www.netkiller.cn ~]# cat /tmp/test.log cat: /tmp/test.log: No such file or directory 经过上面两个实验,你应该明白了在日志打开期间对日志文件做重命名或者删除都会造成日志记录的写入失败。
第一步,终端窗口一中创建一个文件,文件写入一些字符串,这里写入 “one”,然后查看是否成功写入。 [root@www.netkiller.cn ~]# echo one > /tmp/test.log[root@www.netkiller.cn ~]# cat /tmp/test.log one 上面我们可以看到/tmp/test.log文件成功写入一个字符串”one” 第二步,开始追加一些字符串 [root@www.netkiller.cn ~]# cat > /tmp/test.log two 先不要保存(不要发出^D) 第三部,在终端二窗口中清空这个文件 [root@www.netkiller.cn ~]# > /tmp/test.log [root@www.netkiller.cn ~]# cat /tmp/test.log 通过cat查看/tmp/test.log文件,什么也没也表示操作成功。 第四步,完成字符串追加,使用Ctrl+D保存文件,最后使用cat /tmp/test.log 查看内容。 [root@www.netkiller.cn ~]# cat > /tmp/test.log two[root@www.netkiller.cn ~]# cat /tmp/test.log 你会发现/tmp/test.log文件中没有写入任何内容。这表示在日志的访问期间,如果其他程序修改了该日志文件,原来的程序将无法再写入日志。 让我们再来一次,看个究竟 终端一,创建并追加字符串到日志文件中 # echo one > /tmp/test.log# cat /tmp/test.logone# cat >> /tmp/test.logtwo 记得不要保存 终端二,使用lsof查看文件的打开情况 # lsof | grep /tmp/test.logcat 22631 root 1w REG 253,1 0 277445 /tmp/test.log 终端三,开启另一个程序追加字符串到日志文件中 # cat >> /tmp/test.log three 先不要保存(不要发出^D) 终端二,查看文件的打开情况 # lsof | grep /tmp/test.logcat 22631 root 1w REG 253,1 0 277445 /tmp/test.log cat 23350 root 1w REG 253,1 0 277445 /tmp/test.log 终端三,保存three字符串 # cat >> /tmp/test.log three ^D# cat /tmp/test.log three 回到终端一,继续保存内容 # cat > /tmp/test.logtwo ^D# cat /tmp/test.logtwo e 出现新的行情况了,two报道最上面去了,这是因为打开文件默认文件指针是页首,它不知道最后一次文件写入的位置。 你可以反复实验,结果相同。 # cat /tmp/test.logtwo e four five 我为什么没有使用 echo “five” » /tmp/test.log 这种方式追加呢?因为 cat 重定向后只要不发出^D就不会保存文件,而echo是打开文件,获取文件尾部位置,然后追加,最后关闭文件。
我们以 Nginx 为例
[root@www.netkiller.cn ~]# cat /etc/logrotate.d/nginx
/var/log/nginx/*.log { daily
missingok
rotate 52
compress
delaycompress
notifempty
create 640 nginx adm
sharedscripts
postrotate [ -f /var/run/nginx.pid ] && kill -USR1 `cat /var/run/nginx.pid` endscript}
nginx 日志切割后会运行 kill -USR1 这个让nginx 重新创建日志文件或者夺回日志文件的操作权。
那么怎样监控日志被删除,写入权被其他程序夺取?对于程序猿一定很关注这个问题。下面我们讲解怎么监控日志。
Linux 系统可以使用 inotify 开发包来监控文件的状态变化,包括开打,写入,修改权限等等。你需要启动一个进程或者线程监控日志文件的变化,以便随时reload 你的主程序。
prog { sign = null
logfile = /var/log/your.log
thread monitor {
inotify logfile { sign = reload }
}
thread worker {
loop{
f = open(logfile)
loop{
f.append(....)
if(sign == reload) { break }
}
f.close()
}
}
main(){
monitor.start()
worker.start()
}
}
不知你是否看懂,简单的说就是两个并行运行的程序,一个负责日志监控,一个负责干活,一旦日志发生变化就通知主程序 reload。 至于使用进程还是线程去实现,取决于你熟悉那种语言或者你擅长的技术。
将所有服务器的日志都汇总到一处,有几种方法
日志归档常用方法:
首先我来介绍一种简单的方案
我用D语言写了一个程序将 WEB 日志正则分解然后通过管道传递给数据库处理程序
将WEB服务器日志通过管道处理然后写入数据库
处理程序源码
$ vim match.d
import std.regex;
import std.stdio;
import std.string;
import std.array;
void main()
{
// nginx
//auto r = regex(`^(\S+) (\S+) (\S+) \[(.+)\] "([^"]+)" ([0-9]{3}) ([0-9]+) "([^"]+)" "([^"]+)" "([^"]+)"`);
// apache2
auto r = regex(`^(\S+) (\S+) (\S+) \[(.+)\] "([^"]+)" ([0-9]{3}) ([0-9]+) "([^"]+)" "([^"]+)"`);
foreach(line; stdin.byLine)
{
foreach(m; match(line, r)){
//writeln(m.hit);
auto c = m.captures;
c.popFront();
//writeln(c);
auto value = join(c, "\",\"");
auto sql = format("insert into log(remote_addr,unknow,remote_user,time_local,request,status,body_bytes_sent,http_referer,http_user_agent,http_x_forwarded_for) value(\"%s\");", value );
writeln(sql);
}
}
}
编译
$ dmd match.d $ strip match $ ls match match.d match.o
简单用法
$ cat access.log | ./match
高级用法
$ cat access.log | match | mysql -hlocalhost -ulog -p123456 logging
实时处理日志,首先创建一个管道,寻该日志文件写入管道中。
cat 管道名 | match | mysql -hlocalhost -ulog -p123456 logging
这样就可以实现实时日志插入。
![[提示]](/graphics/tip.png) | 提示 |
|---|---|
|
上面程序稍加修改即可实现Hbase, Hypertable 本版 |
Apache 日志管道过滤 CustomLog "| /srv/match >> /tmp/access.log" combined
<VirtualHost *:80>
ServerAdmin webmaster@localhost
#DocumentRoot /var/www
DocumentRoot /www
<Directory />
Options FollowSymLinks
AllowOverride None
</Directory>
#<Directory /var/www/>
<Directory /www/>
Options Indexes FollowSymLinks MultiViews
AllowOverride None
Order allow,deny
allow from all
</Directory>
ScriptAlias /cgi-bin/ /usr/lib/cgi-bin/
<Directory "/usr/lib/cgi-bin">
AllowOverride None
Options +ExecCGI -MultiViews +SymLinksIfOwnerMatch
Order allow,deny
Allow from all
</Directory>
ErrorLog ${APACHE_LOG_DIR}/error.log
# Possible values include: debug, info, notice, warn, error, crit,
# alert, emerg.
LogLevel warn
#CustomLog ${APACHE_LOG_DIR}/access.log combined
CustomLog "| /srv/match >> /tmp/access.log" combined
Alias /doc/ "/usr/share/doc/"
<Directory "/usr/share/doc/">
Options Indexes MultiViews FollowSymLinks
AllowOverride None
Order deny,allow
Deny from all
Allow from 127.0.0.0/255.0.0.0 ::1/128
</Directory>
</VirtualHost>
经过管道转换过的日志效果
$ tail /tmp/access.log
insert into log(remote_addr,unknow,remote_user,time_local,request,status,body_bytes_sent,http_referer,http_user_agent,http_x_forwarded_for) value("192.168.6.30","-","-","21/Mar/2013:16:11:00 +0800","GET / HTTP/1.1","304","208","-","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.22 (KHTML, like Gecko) Chrome/25.0.1364.172 Safari/537.22");
insert into log(remote_addr,unknow,remote_user,time_local,request,status,body_bytes_sent,http_referer,http_user_agent,http_x_forwarded_for) value("192.168.6.30","-","-","21/Mar/2013:16:11:00 +0800","GET /favicon.ico HTTP/1.1","404","501","-","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.22 (KHTML, like Gecko) Chrome/25.0.1364.172 Safari/537.22");
insert into log(remote_addr,unknow,remote_user,time_local,request,status,body_bytes_sent,http_referer,http_user_agent,http_x_forwarded_for) value("192.168.6.30","-","-","21/Mar/2013:16:11:00 +0800","GET / HTTP/1.1","304","208","-","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.22 (KHTML, like Gecko) Chrome/25.0.1364.172 Safari/537.22");
通过定义LogFormat可以直接输出SQL形式的日志
Apache
LogFormat "%v:%p %h %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" vhost_combined
LogFormat "%h %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" combined
LogFormat "%h %l %u %t \"%r\" %>s %O" common
LogFormat "%{Referer}i -> %U" referer
LogFormat "%{User-agent}i" agent
Nginx
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
但对于系统管理员使用grep,awk,sed,sort,uniq分析时造成一定的麻烦。所以我建议仍然采用正则分解
产生有规则日志格式,Apache:
LogFormat \
"\"%h\",%{%Y%m%d%H%M%S}t,%>s,\"%b\",\"%{Content-Type}o\", \
\"%U\",\"%{Referer}i\",\"%{User-Agent}i\""
将access.log文件导入到mysql中
LOAD DATA INFILE '/local/access_log' INTO TABLE tbl_name FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' ESCAPED BY '\\'
# rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm # yum install mongodb
D语言日志处理程序
import std.regex;
//import std.range;
import std.stdio;
import std.string;
import std.array;
void main()
{
// nginx
auto r = regex(`^(\S+) (\S+) (\S+) \[(.+)\] "([^"]+)" ([0-9]{3}) ([0-9]+) "([^"]+)" "([^"]+)" "([^"]+)"`);
// apache2
//auto r = regex(`^(\S+) (\S+) (\S+) \[(.+)\] "([^"]+)" ([0-9]{3}) ([0-9]+) "([^"]+)" "([^"]+)"`);
foreach(line; stdin.byLine)
{
//writeln(line);
//auto m = match(line, r);
foreach(m; match(line, r)){
//writeln(m.hit);
auto c = m.captures;
c.popFront();
//writeln(c);
/*
SQL
auto value = join(c, "\",\"");
auto sql = format("insert into log(remote_addr,unknow,remote_user,time_local,request,status,body_bytes_sent,http_referer,http_user_agent,http_x_forwarded_for) value(\"%s\");", value );
writeln(sql);
*/
// MongoDB
string bson = format("db.logging.access.save({
'remote_addr': '%s',
'remote_user': '%s',
'time_local': '%s',
'request': '%s',
'status': '%s',
'body_bytes_sent':'%s',
'http_referer': '%s',
'http_user_agent': '%s',
'http_x_forwarded_for': '%s'
})",
c[0],c[2],c[3],c[4],c[5],c[6],c[7],c[8],c[9]
);
writeln(bson);
}
}
}
编译日志处理程序
dmd mlog.d
用法
cat /var/log/nginx/access.log | mlog | mongo 192.169.0.5/logging -uxxx -pxxx
处理压错过的日志
# zcat /var/log/nginx/*.access.log-*.gz | /srv/mlog | mongo 192.168.6.1/logging -uneo -pchen
实时采集日志
tail -f /var/log/nginx/access.log | mlog | mongo 192.169.0.5/logging -uxxx -pxxx
上面的方案虽然简单,但太依赖系统管理员,需要配置很多服务器,每种应用软件产生的日志都不同,所以很复杂。如果中途出现故障,将会丢失一部日志。
于是我又回到了起点,所有日志存放在自己的服务器上,定时将他们同步到日志服务器,这样解决了日志归档。远程收集日志,通过UDP协议推送汇总到日志中心,这样解决了日志实时监控、抓取等等对实时性要求较高的需求。
为此我用了两三天写了一个软件,下载地址:https://github.com/netkiller/logging
这种方案并不是最佳的,只是比较适合我的场景,而且我仅用了两三天就完成了软件的开发。后面我会进一步扩展,增加消息队列传送日志的功能。
$ git clone https://github.com/netkiller/logging.git $ cd logging $ python3 setup.py sdist $ python3 setup.py install
安装启动脚本
CentOS
# cp logging/init.d/ulog /etc/init.d
Ubuntu
$ sudo cp init.d/ulog /etc/init.d/
$ service ulog
Usage: /etc/init.d/ulog {start|stop|status|restart}
配置脚本,打开 /etc/init.d/ulog 文件
配置日志中心的IP地址
HOST=xxx.xxx.xxx.xxx
然后配置端口与采集那些日志
done << EOF 1213 /var/log/nginx/access.log 1214 /tmp/test.log 1215 /tmp/$(date +"%Y-%m-%d.%H:%M:%S").log EOF
格式为
Port | Logfile ------------------------------ 1213 /var/log/nginx/access.log 1214 /tmp/test.log 1215 /tmp/$(date +"%Y-%m-%d.%H:%M:%S").log
1213 目的端口号(日志中心端口)后面是你需要监控的日志,如果日志每日产生一个文件写法类似 /tmp/$(date +"%Y-%m-%d.%H:%M:%S").log
| 提示 |
|---|---|
| 每日产生一个新日志文件需要定时重启 ulog 方法是 /etc/init.d/ulog restart |
配置完成后启动推送程序
# service ulog start
查看状态
$ service ulog status 13865 pts/16 S 0:00 /usr/bin/python3 /usr/local/bin/rlog -d -H 127.0.0.1 -p 1213 /var/log/nginx/access.log
停止推送
# service ulog stop
# cp logging/init.d/ucollection /etc/init.d
# /etc/init.d/ucollection
Usage: /etc/init.d/ucollection {start|stop|status|restart}
配置接收端口与保存文件,打开 /etc/init.d/ucollection 文件,看到下面段落
done << EOF 1213 /tmp/nginx/access.log 1214 /tmp/test/test.log 1215 /tmp/app/$(date +"%Y-%m-%d.%H:%M:%S").log 1216 /tmp/db/$(date +"%Y-%m-%d")/mysql.log 1217 /tmp/cache/$(date +"%Y")/$(date +"%m")/$(date +"%d")/cache.log EOF
格式如下,表示接收来自1213端口的数据,并保存到/tmp/nginx/access.log文件中。
Port | Logfile 1213 /tmp/nginx/access.log
如果需要分割日志配置如下
1217 /tmp/cache/$(date +"%Y")/$(date +"%m")/$(date +"%d")/cache.log
上面配置日志文件将会产生在下面的目录中
$ find /tmp/cache/ /tmp/cache/ /tmp/cache/2014 /tmp/cache/2014/12 /tmp/cache/2014/12/16 /tmp/cache/2014/12/16/cache.log
| 提示 |
|---|---|
| 同样,如果分割日志需要重启收集端程序。 |
启动收集端
# service ulog start
停止程序
# service ulog stop
查看状态
$ init.d/ucollection status 12429 pts/16 S 0:00 /usr/bin/python3 /usr/local/bin/collection -d -p 1213 -l /tmp/nginx/access.log 12432 pts/16 S 0:00 /usr/bin/python3 /usr/local/bin/collection -d -p 1214 -l /tmp/test/test.log 12435 pts/16 S 0:00 /usr/bin/python3 /usr/local/bin/collection -d -p 1215 -l /tmp/app/2014-12-16.09:55:15.log 12438 pts/16 S 0:00 /usr/bin/python3 /usr/local/bin/collection -d -p 1216 -l /tmp/db/2014-12-16/mysql.log 12441 pts/16 S 0:00 /usr/bin/python3 /usr/local/bin/collection -d -p 1217 -l /tmp/cache/2014/12/16/cache.log
监控来自1217宽口的数据
$ collection -p 1213 192.168.6.20 - - [16/Dec/2014:15:06:23 +0800] "GET /journal/log.html HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36" 192.168.6.20 - - [16/Dec/2014:15:06:23 +0800] "GET /journal/docbook.css HTTP/1.1" 304 0 "http://192.168.6.2/journal/log.html" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36" 192.168.6.20 - - [16/Dec/2014:15:06:23 +0800] "GET /journal/journal.css HTTP/1.1" 304 0 "http://192.168.6.2/journal/log.html" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36" 192.168.6.20 - - [16/Dec/2014:15:06:23 +0800] "GET /images/by-nc-sa.png HTTP/1.1" 304 0 "http://192.168.6.2/journal/log.html" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36" 192.168.6.20 - - [16/Dec/2014:15:06:23 +0800] "GET /js/q.js HTTP/1.1" 304 0 "http://192.168.6.2/journal/log.html" "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36"
启动后实时将最新日志传送过来
目前方案可能满足基本的日志需求
spring 容器 –> /mnt/logs/project 产生日志文件 –> filebeat 将 /mnt/logs/project 挂载到 /logs 作为 input 输出 –> logstash -> elasticsearch –> kibana
logback 自带 logstash 发送功能,不需要再经过 filebeat 一层转发。
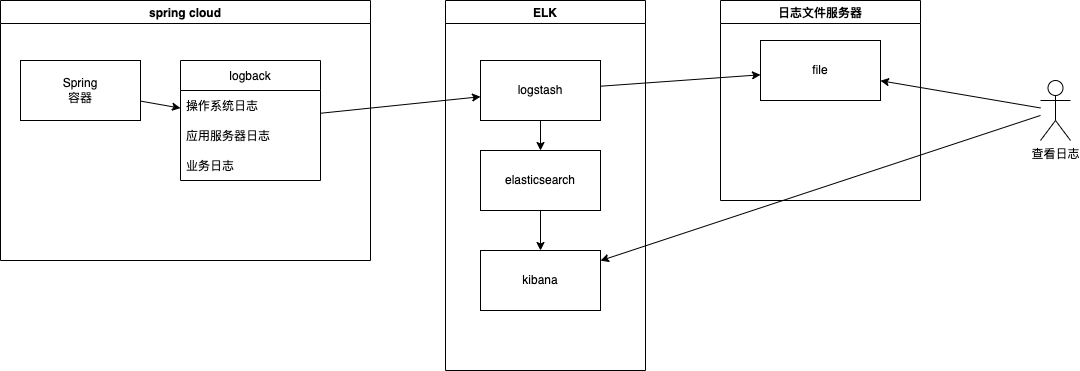
目前所有日志输出在一个文件中,不区分类别,混在一起。
日志分级之后主要有三类:
系统类日志:操作系统产生的/var/log
应用服务器类日志:nginx、spring 包括开发过程中用户调试产生的日志……
业务日志:用户产生的日志,例如下单、充值……
业务日志应用案例举例:用户充值 100 元,会产生业务日志
| 2022-07-30 11:23:00 用户 AAAA 充值 100,账户余额 50 元,充值后 150元 |
| 2022-07-30 11:23:00 用户 AAAA 充值 30,账户余额 150 元,充值后 180元 |
当系统收到黑客攻击,用户余额被恶意更改,此时就可能通过日志核查用户充值情况。业务日志输出要每笔清晰干净,不能与开发调试信息混在一起。
日志提供两种日志查询方案:
文件方案
kibana 方案
工作中观察到并不是所有人都习惯或喜欢使用 kibana,更多的人更习惯使用 tail -f , grep 等 linux 观察日志,所以我们会提供两种查询方式。
所有的日志都会同步到指定的日志中心服务器上。
有关部门会要求公司日志必须保留一定时间,我们自己也需要。
生产环境日志保留一个月,对于冷日志,失去时效的日志,几乎不会在看的日志,每天同步到办公室的备份服务器上,压缩打包存放到 NAS 中。
当需时,重新解压展开。