| 知乎专栏 |
做人工智能机器学习,给学习图片做标签是个体力活。动不动就需要标准上千张图片。
有没有更好的方法呢?
于是便想出了,用AI给学习素材打标签。
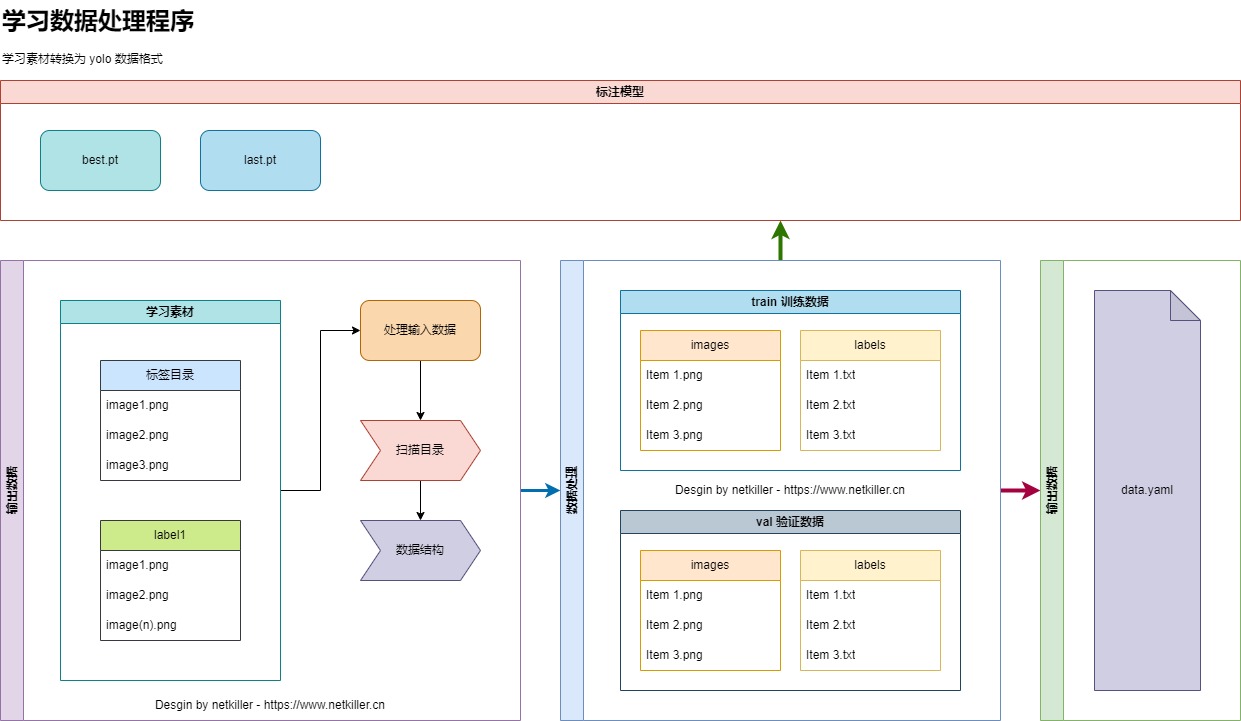 |
首先准备好学习数据,首批数据需要人工标注,可以使用 labelme 和 labelme2yoyo 工具标注,做第一轮学习,后面我们将用这个模型实现 AI 自动标注。
然后使用第一轮训练的bast.pt 模型,对这第二批数据进行处理,生成 yolo 所需的 dataset 数据,包括了 train 训练集, val 验证集。
最后输出 data.yaml 文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
##############################################
# Home : https://www.netkiller.cn
# Author: Neo <netkiller@msn.com>
# Upgrade: 2024-12-12
##############################################
try:
import uuid
import shutil
import os,sys,random,argparse
import yaml
import json
from PIL import Image
from ultralytics import YOLO
except ImportError as err:
print("Import Error: %s" % (err))
exit()
class Tongue():
# background = (22, 255, 39) # 绿幕RGB模式(R22 - G255 - B39),CMYK模式(C62 - M0 - Y100 - K0)
background = (0, 0,0)
expand = 100
border = 10
def __init__(self):
self.basedir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(self.basedir)
# print(basedir)
self.parser = argparse.ArgumentParser(description='自动切割产学习数据')
self.parser.add_argument('--source', type=str, default=None, help='图片来源地址')
self.parser.add_argument('--target', default=None, type=str, help='图片目标地址')
self.parser.add_argument('--imgsz', type=int, default=800, help='长边尺寸',metavar=800)
self.parser.add_argument('--clean', action="store_true", default=False, help='清理之前的数据')
self.parser.add_argument('--md5sum', action="store_true", default=False, help='使用md5作为文件名')
self.parser.add_argument('--uuid', action="store_true", default=False, help='重命名图片为UUID')
self.args = self.parser.parse_args()
def mkdirs(self,path):
if not os.path.exists(path):
os.makedirs(path)
def scanfile(self,path):
files = []
for name in os.listdir(path):
if os.path.isfile(os.path.join(path, name)):
files.append(name)
return (files)
def scandir(self,path):
files = []
for name in os.listdir(path):
if os.path.isdir(os.path.join(path, name)):
files.append(name)
return (files)
def walkdir(self,path):
for dirpath, dirnames, filenames in os.walk(path):
print(f"dirpath={dirpath}, dirnames={dirnames}, filenames={filenames}")
# print(filenames)
def crop(self,original,target,xyxy):
# original = Image.open(source)
width, height = original.size
x0, y0, x1, y1 = map(int, xyxy)
if x0 - self.expand < 0:
x0 = 0
else:
x0 -= self.expand
if y0 - self.expand < 0:
y0 = 0
else:
y0 -= self.expand
if x1 + self.expand > width:
x1 = width
else:
x1 += self.expand
if y1 + self.expand > height:
y1 = height
else:
y1 += self.expand
# print(f"xyxy={xyxy}")
# print(x0, y0, x1, y1)
# crop = tuple(map(int, xyxy))
crop = tuple((x0, y0, x1, y1))
tongue = original.crop(crop)
tongue = self.resize(tongue)
# crop.save(output)
width, height = tongue.size
# width += self.border
# height += self.border
image = Image.new('RGB', (width, height), self.background)
image.paste(tongue, (
int(width / 2) - int(tongue.size[0] / 2), int(height / 2) - int(tongue.size[1] / 2)))
image.save(target)
def boxes(self, source:str):
boxes = self.annotation(source)
if boxes is not None:
xyxy = boxes.xyxy[0].tolist()
# xywh = boxes.xywh[0]
return xyxy
return None
def annotation(self,path):
if not os.path.exists(path):
return None
try:
results = self.model(path)
if len(results):
# print(results[0])
if len(results[0].boxes):
return results[0].boxes[0]
except Exception as e:
# log.error(e)
print("annotation: ",e)
exit()
return None
def resize(self,image):
# from PIL import Image
# 加载图像
# image = Image.open('path_to_your_image.jpg')
# 计算缩放因子
width, height = image.size
# print(width, height)
if max(width,height)> self.args.imgsz:
if width > height :
ratio = width / self.args.imgsz
width = self.args.imgsz
height = int(height / ratio)
else:
ratio = height / self.args.imgsz
width = int(width / ratio)
height = self.args.imgsz
# print(ratio)
# print(width, height)
return image.resize((width, height))
return image
def input(self):
if self.args.clean:
if os.path.exists(self.args.target):
shutil.rmtree(self.args.target)
self.mkdirs(self.args.target)
self.files = self.scanfile(os.path.join(self.args.source))
# print(self.files)
self.model = YOLO(f"{self.basedir}/model/tongue/best.pt")
# YOLO(f"{self.basedir}/model/shebei/best.pt")
def process(self):
for file in self.files:
source = os.path.join(self.args.source, file)
target = os.path.join(self.args.target, file)
# print(file)
try:
original = Image.open(source)
width, height = original.size
# print(target)
if max(width,height) < self.args.imgsz :
shutil.copyfile(source, target)
else:
xyxy=self.boxes(source)
self.crop(original, target,xyxy)
# print(f"COPY train source={source}, target={target}")
except Exception as e:
# log.error(e)
print("process: ", e)
exit()
def output(self):
pass
def main(self):
# print(self.args)
if self.args.source and self.args.target:
self.input()
self.process()
self.output()
else:
self.parser.print_help()
exit()
if __name__ == "__main__":
try:
tongue = Tongue()
tongue.main()
except KeyboardInterrupt as e:
print(e)
代码讲训练数据转换为 YOLO 数据库集
#!/usr/bin/env python
# -*- coding: utf-8 -*-
##############################################
# Home : https://www.netkiller.cn
# Author: Neo <netkiller@msn.com>
# Upgrade: 2024-12-11
##############################################
import uuid
try:
import shutil
import os,sys,random,argparse
import yaml
import json
from PIL import Image
from ultralytics import YOLO
except ImportError as err:
print("Import Error: %s" % (err))
exit()
class Dataset:
train = {}
val = {}
test = {}
classes = []
data = {}
def __str__(self):
return (f"classes={self.classes} data={len(self.data)} train={len(self.train)} val={len(self.val)} test={len(self.test)}")
class Tongue():
# background = (22, 255, 39) # 绿幕RGB模式(R22 - G255 - B39),CMYK模式(C62 - M0 - Y100 - K0)
background = (0, 0,0)
def __init__(self):
self.basedir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(self.basedir)
# print(basedir)
# exit()
self.dataset = Dataset()
self.parser = argparse.ArgumentParser(description='自动切割产学习数据')
self.parser.add_argument('--source', type=str, default=None, help='图片来源地址')
self.parser.add_argument('--target', default=None, type=str, help='图片目标地址')
self.parser.add_argument('--val-number', type=int, default=10, help='检验数量',metavar=10)
# self.parser.add_argument('--classes', type=str, default=None, help='classes')
self.parser.add_argument('--clean', action="store_true", default=False, help='清理之前的数据')
self.parser.add_argument('--crop', action="store_true", default=False, help='裁剪')
self.parser.add_argument('--uuid', action="store_true", default=False, help='裁剪')
self.args = self.parser.parse_args()
def mkdirs(self,path):
if not os.path.exists(path):
os.makedirs(path)
def scanfile(self,path):
files = []
for name in os.listdir(path):
if os.path.isfile(os.path.join(path, name)):
files.append(name)
return (files)
def scandir(self,path):
files = []
for name in os.listdir(path):
if os.path.isdir(os.path.join(path, name)):
files.append(name)
return (files)
def walkdir(self,path):
for dirpath, dirnames, filenames in os.walk(path):
print(f"dirpath={dirpath}, dirnames={dirnames}, filenames={filenames}")
# print(filenames)
def datafile(self):
# 编写yaml文件
classes_txt = {i: self.dataset.classes[i] for i in range(len(self.dataset.classes))} # 标签类别
data = {
'path': os.path.join(os.getcwd(), self.args.target),
'train': "train/images",
'val': "val/images",
'test': "test/images",
'names': classes_txt
# 'nc': len(self.classes)
}
with open(os.path.join(self.args.target , 'data.yaml'), 'w', encoding="utf-8") as file:
yaml.dump(data, file, allow_unicode=True)
# print("标签:", self.classes)
def images(self):
try:
for label, files in self.dataset.data.items():
self.dataset.train[label] = []
for name in files:
# print(name)
source = os.path.join(self.args.source, label, name)
# print(input)
if self.args.uuid:
uuid.uuid4()
extension = os.path.splitext(name)[1]
target = os.path.join(self.args.target, 'train/images', f"{uuid.uuid4()}{extension}")
else:
target = os.path.join(self.args.target, 'train/images', name)
# print(target)
self.dataset.train[label].append(target)
if self.args.crop:
boxes = self.annotation(source)
if boxes is not None:
xyxy = boxes.xyxy[0]
xywh = boxes.xywh[0]
original = Image.open(source)
# width, height = original.size
# x0, y0, x1, y1 = map(int, results[0].boxes[0].xyxy[0])
tongue = original.crop(tuple(map(int, xyxy)))
# crop.save(output)
width, height = tongue.size
width += 50
height += 50
image = Image.new('RGB', (width, height), self.background)
image.paste(tongue, (
int(width / 2) - int(tongue.size[0] / 2), int(height / 2) - int(tongue.size[1] / 2)))
image.save(target)
else:
# print(f"COPY source={source}, target={target}")
shutil.copyfile(source, target)
# print(self.dataset.train)
except Exception as e:
# log.error(e)
print("images train: ", e)
exit()
try:
for label, files in self.dataset.data.items():
if len(files) < self.args.val_number:
self.args.val_number = len(files)
vals = random.sample(files, self.args.val_number)
self.dataset.val[label] = vals
for name in vals:
shutil.copyfile(os.path.join(self.args.source, label,name), os.path.join(self.args.target, 'val/images',name))
except Exception as e:
# log.error(e)
print("images val: ", e)
exit()
# exit()
def labels(self):
try:
for label, files in self.dataset.train.items():
for name in files:
# input =os.path.join(self.args.target, 'train/images', name)
# print(input)
boxes = self.annotation(name)
# print(boxes)
if boxes is not None:
filename, extension = os.path.splitext(os.path.basename(name))
print(filename)
xywhn = boxes.xywhn[0]
index = self.dataset.classes.index(label)
content = f"{index} {xywhn[0]} {xywhn[1]} {xywhn[2]} {xywhn[3]}"
# print(content)
with open(os.path.join(self.args.target, 'train/labels', filename + '.txt'), "w") as f:
f.write(content)
except Exception as e:
# log.error(e)
print("train labels", e)
exit()
try:
for label, files in self.dataset.val.items():
for name in files:
filename, extension = os.path.splitext(name)
# print(filename)
input = os.path.join(self.args.target, 'val/images', name)
boxes = self.annotation(input)
if boxes is not None:
xywhn = boxes.xywhn[0]
index = self.dataset.classes.index(label)
content = f"{index} {xywhn[0]} {xywhn[1]} {xywhn[2]} {xywhn[3]}"
# print(content)
with open(os.path.join(self.args.target, 'val/labels', filename + '.txt'), "w") as f:
f.write(content)
except Exception as e:
# log.error(e)
print("val labels",e)
exit()
def annotation(self,path):
if not os.path.exists(path):
return None
model = self.models['tongue']
try:
results = model(path)
if len(results):
# print(results[0])
if len(results[0].boxes):
# print(results[0].boxes)
# if len(results[0].boxes[0].xyxy):
# print(results[0].boxes[0].xyxy[0])
# # log.info(f"Image filename={filename}")
# print(results[0].boxes[0].xywhn[0])
# return results[0].boxes[0].xywhn[0]
return results[0].boxes[0]
except Exception as e:
# log.error(e)
print("annotation: ",e)
exit()
return None
def input(self):
directory = [
# 'labels/train','images/train','labels/val', 'images/val','labels/test', 'images/test'
'train/labels', 'train/images', 'val/labels', 'val/images', 'test/labels', 'test/images'
]
for dir in directory:
self.mkdirs(os.path.join(self.args.target,dir))
self.dataset.classes= self.scandir(self.args.source)
# print(self.dataset.classes)
for cls in self.dataset.classes:
self.dataset.data[cls] = self.scanfile(os.path.join(self.args.source, cls))
# print(self.dataset)
# exit()
pass
def process(self):
self.images()
self.labels()
pass
def output(self):
self.datafile()
pass
def main(self):
# print(self.args)
if self.args.clean:
shutil.rmtree(self.args.target)
if self.args.source and self.args.target:
self.models = {
'tongue': YOLO(f"{self.basedir}/model/tongue/best.pt"),
'shebei': YOLO(f"{self.basedir}/model/shebei/best.pt")
}
self.input()
self.process()
self.output()
else:
self.parser.print_help()
exit()
# if args.classes:
# self.classes = args.classes
# else:
# self.parser.print_help()
# # classes = args.classes
# exit(128)
if __name__ == "__main__":
try:
tongue = Tongue()
tongue.main()
except KeyboardInterrupt as e:
print(e)
命令行帮助信息
D:\workspace\netkiller\.venv\Scripts\python.exe D:\workspace\netkiller\bin\converter.py
usage: converter.py [-h] [--source SOURCE] [--target TARGET] [--val-number 10]
[--clean] [--crop] [--uuid]
自动切割产学习数据
options:
-h, --help show this help message and exit
--source SOURCE 图片来源地址
--target TARGET 图片目标地址
--val-number 10 检验数量
--clean 清理之前的数据
--crop 裁剪
--uuid 唯一文件名
(.venv) PS D:\workspace\netkiller> python.exe .\bin\converter.py --source .\datasets\test --target .\datasets\netkiller --clean --val-number 100 --uuid
#!/usr/bin/env python
# -*- coding: utf-8 -*-
##############################################
# Home : https://www.netkiller.cn
# Author: Neo <netkiller@msn.com>
# Upgrade: 2024-12-13
##############################################
try:
import uuid,hashlib
import glob
import shutil
import os,sys,random,argparse
import yaml
from tqdm import tqdm
from PIL import Image
from ultralytics import YOLO
except ImportError as err:
print("Import Error: %s" % (err))
exit()
class AutoLabel():
classes = []
labels = {}
def __init__(self):
self.basedir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(self.basedir)
# print(basedir)
self.parser = argparse.ArgumentParser(description='自动标注数据')
self.parser.add_argument('--source', type=str, default=None, help='图片来源地址')
self.parser.add_argument('--target', default=None, type=str, help='图片目标地址')
self.parser.add_argument('--model', type=str, default=None, help='模型',metavar="")
self.parser.add_argument('--output', type=str, default=None, help='输出识别图像', metavar="")
self.parser.add_argument('--clean', action="store_true", default=False, help='清理之前的数据')
self.parser.add_argument('--verbose', action="store_true", default=False, help='过程输出')
# self.parser.add_argument('--uuid', action="store_true", default=False, help='重命名图片为UUID')
self.args = self.parser.parse_args()
def mkdirs(self,path):
if not os.path.exists(path):
os.makedirs(path)
def scanfile(self,path):
files = []
for name in os.listdir(path):
if os.path.isfile(os.path.join(path, name)):
files.append(name)
return (files)
def scandir(self,path):
files = []
for name in os.listdir(path):
if os.path.isdir(os.path.join(path, name)):
files.append(name)
return (files)
def walkdir(self,path):
for dirpath, dirnames, filenames in os.walk(path):
print(f"dirpath={dirpath}, dirnames={dirnames}, filenames={filenames}")
# print(filenames)
def label(self, source:str):
# print(source)
if not os.path.exists(source):
return None
try:
results = self.model(source,verbose=self.args.verbose)
# print(results)
for result in results:
boxes = result.boxes # 获取边界框信息
# probs = result.probs # 获取分类概率
# names = result.names
# print(boxes)
# print(probs)
# print(names)
# if boxes is not None:
# print(boxes.cls.tolist())
# print(boxes.xywhn.tolist())
if not self.classes:
for index,name in result.names.items():
self.classes.append(name)
if self.args.output:
result.save(filename=os.path.join(self.args.output,os.path.basename(source)))
lines = []
for n in range(len(boxes.cls)):
index = int(boxes.cls[n])
xywhn = boxes.xywhn[n]
line = f"{index} {xywhn[0]} {xywhn[1]} {xywhn[2]} {xywhn[3]}"
# print(line)
# label = names[int(box.cls)]
lines.append(line)
name, extension = os.path.splitext(os.path.basename(source))
self.labels[name] = "\r\n".join(lines)
except Exception as e:
# log.error(e)
print("annotation: ",e)
exit()
return None
def input(self):
try:
if self.args.clean:
shutil.rmtree(self.args.target)
shutil.rmtree(self.args.output)
# if os.path.exists(self.args.target):
# files = glob.glob(os.path.join(self.args.target,'*.txt'))
# for file in files:
# os.remove(file)
self.mkdirs(self.args.target)
self.mkdirs(self.args.output)
# self.files = self.scanfile(os.path.join(self.args.source))
self.files =glob.glob(os.path.join(self.args.source, '*.jpg'))
# print(self.files)
except Exception as e:
# log.error(e)
print("input: ", e)
exit()
def process(self):
with tqdm(total=len(self.files), ncols=150) as progress:
for source in self.files:
progress.set_description(os.path.basename(source))
target = os.path.join(self.args.target, os.path.basename(source))
# print(f"copy source={source}, target={target}")
try:
shutil.copyfile(source, target)
self.label(source)
except Exception as e:
# log.error(e)
progress.close()
print("process: ", e)
exit()
progress.update(1)
def output(self):
# print(content)
for name, label in self.labels.items():
target = os.path.join(self.args.target, f"{name}.txt")
with open(target, "w") as file:
file.write(label)
with open(os.path.join(self.args.target,'classes.txt'), "w") as file:
# for line in self.classes:
# file.write(line)
file.writelines([line+'\n' for line in self.classes])
pass
def main(self):
if self.args.model :
self.model = YOLO(self.args.model)
else:
self.model = YOLO(f"{self.basedir}/model/tongue/best.pt")
# print(self.args)
if self.args.source and self.args.target:
self.input()
self.process()
self.output()
else:
self.parser.print_help()
exit()
if __name__ == "__main__":
try:
run = AutoLabel()
run.main()
except KeyboardInterrupt as e:
print(e)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
##############################################
# Home : https://www.netkiller.cn
# Author: Neo <netkiller@msn.com>
# Upgrade: 2024-12-11
##############################################
import glob
import os,sys,argparse
import random
from tqdm import tqdm
import yaml,shutil
import cv2
class LabelimgToYolo():
# background = (22, 255, 39) # 绿幕RGB模式(R22 - G255 - B39),CMYK模式(C62 - M0 - Y100 - K0)
background = (0, 0,0)
def __init__(self):
self.basedir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(self.basedir)
self.parser = argparse.ArgumentParser(description='Yolo 工具 https://www.netkiller.cn')
self.parser.add_argument('--source', type=str, default=None, help='图片来源地址')
self.parser.add_argument('--target', default=None, type=str, help='图片目标地址')
# self.parser.add_argument('--diseases', type=str, default=None, help='疾病分类')
self.parser.add_argument('--val', type=int, default=10, help='检验数量',metavar=10)
self.parser.add_argument('--clean', action="store_true", default=False, help='清理之前的数据')
self.parser.add_argument('--crop', action="store_true", default=False, help='裁剪')
# self.parser.add_argument('--uuid', action="store_true", default=False, help='重命名图片为UUID')
self.parser.add_argument('--check', action="store_true", default=False, help='图片检查 corrupt JPEG restored and saved')
self.args = self.parser.parse_args()
def mkdirs(self,path):
if not os.path.exists(path):
os.makedirs(path)
def input(self):
if self.args.clean:
if os.path.exists(self.args.target):
shutil.rmtree(self.args.target)
self.mkdirs(os.path.join(self.args.target))
directory = [
'train/labels', 'train/images', 'val/labels', 'val/images', 'test/labels', 'test/images'
]
with tqdm(total=len(directory), ncols=100) as progress:
progress.set_description("init")
for dir in directory:
self.mkdirs(os.path.join(self.args.target, dir))
progress.update(1)
def process(self):
images = glob.glob('*.jpg', root_dir=self.args.source)
labels = glob.glob('*.txt', root_dir=self.args.source)
with tqdm(total=len(images), ncols=100) as progress:
progress.set_description("%s" % 'train/images')
for image in images:
if self.args.check:
source = os.path.join(self.args.source, image)
target = os.path.join(self.args.target, 'train/images', image)
img = cv2.imread(source)
cv2.imwrite(target, img)
else:
shutil.copy(os.path.join(self.args.source, image), os.path.join(self.args.target, 'train/images'))
progress.update(1)
with tqdm(total=len(labels), ncols=100) as progress:
progress.set_description("%s" % 'train/labels')
for label in labels:
if label == 'classes.txt':
continue
shutil.copy(os.path.join(self.args.source,label), os.path.join(self.args.target,'train/labels'))
progress.update(1)
if len(images) < self.args.val:
self.args.val = len(images)
vals = random.sample(images, self.args.val)
# self.dataset.val[label] = []
for image in vals:
shutil.copy(os.path.join(self.args.source,image), os.path.join(self.args.target, 'val/images'))
filename, extension = os.path.splitext(os.path.basename(image))
label = os.path.join(self.args.source,f"{filename}.txt")
try:
shutil.copy(label, os.path.join(self.args.target, 'val/labels'))
except Exception as e:
print(e)
def output(self):
classes = []
with open(os.path.join(self.args.source,'classes.txt')) as file:
for line in file:
classes.append(line.strip())
# print(classes)
names = {i: classes[i] for i in range(len(classes))} # 标签类别
data = {
'path': os.path.join(os.getcwd(), self.args.target),
'train': "train/images",
'val': "val/images",
'test': "test/images",
'names': names
# 'nc': len(self.classes)
}
with open(os.path.join(self.args.target, 'data.yaml'), 'w', encoding="utf-8") as file:
yaml.dump(data, file, allow_unicode=True)
def main(self):
if self.args.source and self.args.target:
self.input()
self.process()
self.output()
else:
self.parser.print_help()
exit()
if __name__ == "__main__":
try:
run = LabelimgToYolo()
run.main()
except KeyboardInterrupt as e:
print(e)
V2 版本
#!/usr/bin/env python
# -*- coding: utf-8 -*-
##############################################
# Home : https://www.netkiller.cn
# Author: Neo <netkiller@msn.com>
# Upgrade: 2024-12-12
##############################################
import glob
import os,sys,argparse
import random
from texttable import Texttable
from tqdm import tqdm
import yaml,shutil
import cv2
import logging
class LabelimgToYolo():
# background = (22, 255, 39) # 绿幕RGB模式(R22 - G255 - B39),CMYK模式(C62 - M0 - Y100 - K0)
background = (0, 0,0)
def __init__(self):
self.basedir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(self.basedir)
# 日志记录基本设置
logfile = os.path.splitext(__file__)[0]
logging.basicConfig(filename=f"{logfile}.log", level=logging.DEBUG, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
self.parser = argparse.ArgumentParser(description='Yolo 工具 V2.0 - Design by netkiller - https://www.netkiller.cn')
self.parser.add_argument('--source', type=str, default=None, help='图片来源地址')
self.parser.add_argument('--target', default=None, type=str, help='图片目标地址')
# self.parser.add_argument('--diseases', type=str, default=None, help='疾病分类')
self.parser.add_argument('--val', type=int, default=10, help='检验数量',metavar=10)
self.parser.add_argument('--clean', action="store_true", default=False, help='清理之前的数据')
self.parser.add_argument('--crop', action="store_true", default=False, help='裁剪')
# self.parser.add_argument('--uuid', action="store_true", default=False, help='重命名图片为UUID')
self.parser.add_argument('--check', action="store_true", default=False, help='图片检查 corrupt JPEG restored and saved')
self.args = self.parser.parse_args()
self.classes = []
self.data = {}
self.missed = []
self.logger = logging.getLogger("LabelimgToYolo")
def mkdirs(self,path):
if not os.path.exists(path):
os.makedirs(path)
def input(self):
if self.args.clean:
if os.path.exists(self.args.target):
shutil.rmtree(self.args.target)
self.mkdirs(os.path.join(self.args.target))
directory = [
'train/labels', 'train/images', 'val/labels', 'val/images', 'test/labels', 'test/images'
]
with tqdm(total=len(directory), ncols=100) as progress:
progress.set_description("init")
for dir in directory:
self.mkdirs(os.path.join(self.args.target, dir))
progress.update(1)
with open(os.path.join(self.args.source, 'classes.txt')) as file:
for line in file:
self.classes.append(line.strip())
self.data[line.strip()] = []
self.logger.info(f"classes={self.classes}")
# print(self.classes)
def process(self):
# images = glob.glob('*.jpg', root_dir=self.args.source)
labels = glob.glob('*.txt', root_dir=self.args.source)
with tqdm(total=len(labels), ncols=100) as progress:
progress.set_description("%s" % 'train/labels')
for label in labels:
if label == 'classes.txt':
continue
source = os.path.join(self.args.source,label)
target = os.path.join(self.args.target,'train/labels')
name, extension = os.path.splitext(label)
self.logger.debug(f"train/labels source={source} target={target} name={name}")
with open(source) as file:
for line in file:
index = line.strip().split(" ")[0]
self.data[self.classes[int(index)]].append(name)
self.logger.debug(f"line={line.strip()} index={index} label={self.classes[int(index)]}")
shutil.copy(source, target)
progress.update(1)
with tqdm(total=len(labels), ncols=100) as progress:
progress.set_description("%s" % 'train/images')
for label in labels:
if label == 'classes.txt':
continue
name, extension = os.path.splitext(label)
filename = f"{name}.jpg"
if os.path.isfile(os.path.join(self.args.source,filename)):
source = os.path.join(self.args.source, filename)
target = os.path.join(self.args.target, 'train/images', filename)
self.logger.debug(f"train/images source={source} target={target} name={name}")
if self.args.check:
img = cv2.imread(source)
cv2.imwrite(target, img)
else:
shutil.copy(source, target)
else:
self.missed.append(filename)
self.logger.warning(f"missing {filename}")
progress.update(1)
for label, files in self.data.items():
if len(files) < self.args.val:
self.args.val = len(files)
vals = random.sample(files, self.args.val)
# self.logger.debug(f"val/images label={label} files={files}")
for name in vals:
# filename, extension = os.path.splitext(os.path.basename(image))
try:
shutil.copy(os.path.join(self.args.source, f"{name}.jpg"),os.path.join(self.args.target, 'val/images'))
shutil.copy(os.path.join(self.args.source,f"{name}.txt"), os.path.join(self.args.target, 'val/labels'))
except Exception as e:
self.logger.error(f"val {repr(e)} name={name}")
def output(self):
names = {i: self.classes[i] for i in range(len(self.classes))} # 标签类别
data = {
'path': os.path.join(os.getcwd(), self.args.target),
'train': "train/images",
'val': "val/images",
'test': "test/images",
'names': names
# 'nc': len(self.classes)
}
with open(os.path.join(self.args.target, 'data.yaml'), 'w', encoding="utf-8") as file:
yaml.dump(data, file, allow_unicode=True)
def report(self):
tables = [["标签", "数量"]]
for label,files in self.data.items():
tables.append([label,len(files)])
table = Texttable(max_width=160)
table.add_rows(tables)
print(table.draw())
for file in self.missed:
self.logger.warning(f"丢失文件 {file}")
def main(self):
if self.args.source and self.args.target:
self.logger.info("Start")
self.input()
self.process()
self.output()
self.report()
self.logger.info("Done")
else:
self.parser.print_help()
exit()
if __name__ == "__main__":
try:
run = LabelimgToYolo()
run.main()
except KeyboardInterrupt as e:
print(e)
V2.5板
#!/usr/bin/env python
# -*- coding: utf-8 -*-
##############################################
# Home : https://www.netkiller.cn
# Author: Neo <netkiller@msn.com>
# Upgrade: 2024-12-29
##############################################
import argparse
import glob
import logging
import os
import random
import sys
import cv2
import shutil
import yaml
from texttable import Texttable
from tqdm import tqdm
class LabelimgToYolo():
# background = (22, 255, 39) # 绿幕RGB模式(R22 - G255 - B39),CMYK模式(C62 - M0 - Y100 - K0)
background = (0, 0, 0)
def __init__(self):
self.basedir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(self.basedir)
# 日志记录基本设置
logfile = os.path.join(self.basedir, 'logs', f"{os.path.splitext(__file__)[0]}.log")
logging.basicConfig(filename=logfile, level=logging.DEBUG,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
self.parser = argparse.ArgumentParser(
description='Yolo 工具 V2.5 - Design by netkiller - https://www.netkiller.cn')
self.parser.add_argument('--source', type=str, default=None, help='图片来源地址')
self.parser.add_argument('--target', default=None, type=str, help='图片目标地址')
# self.parser.add_argument('--diseases', type=str, default=None, help='疾病分类')
self.parser.add_argument('--val', type=int, default=10, help='检验数量', metavar=10)
self.parser.add_argument('--clean', action="store_true", default=False, help='清理之前的数据')
self.parser.add_argument('--crop', action="store_true", default=False, help='裁剪')
self.parser.add_argument('--check', action="store_true", default=False,
help='图片检查 corrupt JPEG restored and saved')
self.parser.add_argument('--label', action="store_true", default=False, help='标签统计')
self.args = self.parser.parse_args()
self.classes = []
self.data = {}
self.missed = []
self.logger = logging.getLogger("LabelimgToYolo")
def mkdirs(self, path):
if not os.path.exists(path):
os.makedirs(path)
def input(self):
if self.args.clean:
if os.path.exists(self.args.target):
shutil.rmtree(self.args.target)
self.mkdirs(os.path.join(self.args.target))
directory = [
'train/labels', 'train/images', 'val/labels', 'val/images', 'test/labels', 'test/images'
]
with tqdm(total=len(directory), ncols=100) as progress:
progress.set_description("init")
for dir in directory:
self.mkdirs(os.path.join(self.args.target, dir))
progress.update(1)
with open(os.path.join(self.args.source, 'classes.txt')) as file:
for line in file:
self.classes.append(line.strip())
self.data[line.strip()] = []
self.logger.info(f"classes={self.classes}")
# print(self.classes)
def process(self):
# images = glob.glob('*.jpg', root_dir=self.args.source)
labels = glob.glob('*.txt', root_dir=self.args.source)
with tqdm(total=len(labels), ncols=100) as progress:
progress.set_description("%s" % 'train/labels')
for label in labels:
if label == 'classes.txt':
continue
source = os.path.join(self.args.source, label)
target = os.path.join(self.args.target, 'train/labels')
name, extension = os.path.splitext(label)
self.logger.debug(f"train/labels source={source} target={target} name={name}")
with open(source) as file:
for line in file:
index = line.strip().split(" ")[0]
self.data[self.classes[int(index)]].append(name)
self.logger.debug(f"line={line.strip()} index={index} label={self.classes[int(index)]}")
if not self.args.label:
shutil.copy(source, target)
progress.update(1)
if self.args.label:
return
with tqdm(total=len(labels), ncols=100) as progress:
progress.set_description("%s" % 'train/images')
for label in labels:
if label == 'classes.txt':
continue
name, extension = os.path.splitext(label)
filename = f"{name}.jpg"
if os.path.isfile(os.path.join(self.args.source, filename)):
source = os.path.join(self.args.source, filename)
target = os.path.join(self.args.target, 'train/images', filename)
self.logger.debug(f"train/images source={source} target={target} name={name}")
if self.args.check:
img = cv2.imread(source)
cv2.imwrite(target, img)
else:
shutil.copy(source, target)
else:
self.missed.append(filename)
self.logger.warning(f"missing {filename}")
progress.update(1)
# for label, files in self.data.items():
if len(labels) < self.args.val:
self.args.val = len(labels)
vals = random.sample(labels, self.args.val)
with tqdm(total=len(vals), ncols=100) as progress:
progress.set_description("%s" % 'val')
# self.logger.debug(f"val/images label={label} files={files}")
for file in vals:
if file == 'classes.txt':
continue
name, extension = os.path.splitext(os.path.basename(file))
try:
shutil.copy(os.path.join(self.args.source, f"{name}.jpg"),
os.path.join(self.args.target, 'val/images', f"{name}.jpg"))
shutil.copy(os.path.join(self.args.source, f"{name}.txt"),
os.path.join(self.args.target, 'val/labels', f"{name}.txt"))
except Exception as e:
self.logger.error(f"val {repr(e)} name={name}")
progress.update(1)
def output(self):
names = {i: self.classes[i] for i in range(len(self.classes))} # 标签类别
data = {
'path': os.path.join(os.getcwd(), self.args.target),
'train': "train/images",
'val': "val/images",
'test': "test/images",
'names': names
# 'nc': len(self.classes)
}
with open(os.path.join(self.args.target, 'data.yaml'), 'w', encoding="utf-8") as file:
yaml.dump(data, file, allow_unicode=True)
def report(self):
tables = [["标签", "数量"]]
for label, files in self.data.items():
tables.append([label, len(files)])
table = Texttable(max_width=160)
table.add_rows(tables)
print(table.draw())
for file in self.missed:
self.logger.warning(f"丢失文件 {file}")
def main(self):
if self.args.source and self.args.target:
self.logger.info("Start")
self.input()
self.process()
self.output()
self.report()
self.logger.info("Done")
else:
self.parser.print_help()
exit()
if __name__ == "__main__":
try:
run = LabelimgToYolo()
run.main()
except KeyboardInterrupt as e:
print(e)
Yolo 标签工具,转换 Labelimg 到 Yolo 数据集 V3
#!/usr/bin/env python
# -*- coding: utf-8 -*-
##############################################
# Home : https://www.netkiller.cn
# Author: Neo <netkiller@msn.com>
# Upgrade: 2024-02-12
# 增加递归目录,从每个标签中抽取验证数据
##############################################
import argparse
import glob
import logging
import os
import random
import shutil
import sys
import uuid
import cv2
import yaml
from texttable import Texttable
from tqdm import tqdm
class LabelimgToYolo():
# background = (22, 255, 39) # 绿幕RGB模式(R22 - G255 - B39),CMYK模式(C62 - M0 - Y100 - K0)
background = (0, 0, 0)
def __init__(self):
self.basedir =os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# print(self.basedir)
# print(logfile)
# sys.path.append(self.basedir)
# 日志记录基本设置
logfile = os.path.join(self.basedir, 'logs', f"{os.path.splitext(os.path.basename(__file__))[0]}.log")
logging.basicConfig(filename=logfile, level=logging.DEBUG,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
self.parser = argparse.ArgumentParser(
description='Yolo 工具 V3.0 - Design by netkiller - https://www.netkiller.cn')
self.parser.add_argument('--source', type=str, default=None, help='图片来源地址')
self.parser.add_argument('--target', default=None, type=str, help='图片目标地址')
self.parser.add_argument('--classes', type=str, default=None, help='classes.txt 文件')
self.parser.add_argument('--val', type=int, default=10, help='检验数量', metavar=10)
self.parser.add_argument('--clean', action="store_true", default=False, help='清理之前的数据')
self.parser.add_argument('--crop', action="store_true", default=False, help='裁剪')
self.parser.add_argument('--uuid', action="store_true", default=False, help='输出文件名使用UUID')
self.parser.add_argument('--check', action="store_true", default=False,
help='图片检查 corrupt JPEG restored and saved')
self.parser.add_argument('--label', action="store_true", default=False, help='标签统计')
self.args = self.parser.parse_args()
self.classes = []
self.lables = {}
self.missed = []
self.logger = logging.getLogger("LabelimgToYolo")
def mkdirs(self, path):
if not os.path.exists(path):
os.makedirs(path)
def input(self):
if self.args.clean:
if os.path.exists(self.args.target):
shutil.rmtree(self.args.target)
self.mkdirs(os.path.join(self.args.target))
directory = [
'train/labels', 'train/images', 'val/labels', 'val/images', 'test/labels', 'test/images'
]
classes = os.path.join(self.args.source, 'classes.txt')
if not os.path.isfile(classes):
print(f"classes.txt 文件不存在: {classes}")
self.logger.error(f"classes={f"classes.txt 文件不存在!"}")
exit()
with tqdm(total=len(directory)+1, ncols=120) as progress:
with open(classes) as file:
progress.set_description(F"init {classes}")
for line in file:
self.classes.append(line.strip())
self.lables[line.strip()] = []
self.logger.info(f"classes={self.classes}")
progress.update(1)
for dir in directory:
progress.set_description(f"init {dir}")
self.mkdirs(os.path.join(self.args.target, dir))
progress.update(1)
# filepath = glob.glob(f'{self.args.source}/**/*.txt', recursive=True)
# for filename in filepath:
# print(filename)
# print(self.classes)
def process(self):
# images = glob.glob('*.jpg', root_dir=self.args.source)
# labels = glob.glob('*.txt', root_dir=self.args.source)
files = glob.glob(f'{self.args.source}/**/*.txt', recursive=True)
with tqdm(total=len(files), ncols=120) as images, tqdm(total=len(files), ncols=120) as train:
for source in files:
if source.endswith('classes.txt') :
train.update(1)
continue
train.set_description(f'train/labels: {source}')
uuid4 = uuid.uuid4()
if self.args.uuid:
target = os.path.join(self.args.target, 'train/labels', f"{uuid4}.txt")
else:
target = os.path.join(self.args.target, 'train/labels', os.path.basename(source))
name, extension = os.path.splitext(os.path.basename(target))
with open(source) as file:
for line in file:
index = line.strip().split(" ")[0]
label = self.classes[int(index)]
# if label not in self.lables:
# self.lables[label] = []
self.lables[label].append(name)
self.logger.debug(f"index={index} label={label} file={name} line={line.strip()} ")
if not self.args.label:
shutil.copy(source, target)
self.logger.debug(f"train/labels source={source} target={target} name={name}")
train.update(1)
if not self.args.label:
name, extension = os.path.splitext(os.path.basename(source))
source = os.path.join(os.path.dirname(source),f"{name}.jpg")
images.set_description(f'train/images: {source}')
if os.path.isfile(source):
if self.args.uuid:
target = os.path.join(self.args.target, 'train/images', f"{uuid4}.jpg")
else:
target = os.path.join(self.args.target, 'train/images', os.path.basename(source))
self.logger.debug(f"train/images source={source} target={target} name={name}")
if self.args.check:
img = cv2.imread(source)
cv2.imwrite(target, img)
else:
shutil.copy(source, target)
else:
self.missed.append(source)
self.logger.warning(f"missing {source}")
images.update(1)
# print(self.lables)
for label, files in self.lables.items():
if len(files) == 0:
continue
if len(files) < self.args.val:
valnumber = len(files)
else:
valnumber = self.args.val
vals = random.sample(files, valnumber)
# print(f"label={label} files={len(files)} val={len(vals)}")
with tqdm(total=len(vals), ncols=120) as progress:
for file in vals:
progress.set_description(f"val/label {label}")
name, extension = os.path.splitext(os.path.basename(file))
try:
shutil.copy(os.path.join(self.args.target, 'train/labels', f"{name}.txt"),
os.path.join(self.args.target, 'val/labels', f"{name}.txt"))
self.logger.info(f"val/labels label={label} file={name}.txt")
shutil.copy(os.path.join(self.args.target, 'train/images', f"{name}.jpg"),
os.path.join(self.args.target, 'val/images', f"{name}.jpg"))
self.logger.info(f"val/images label={label} file={name}.jpg")
except Exception as e:
self.logger.error(f"val {repr(e)} name={name}")
progress.update(1)
def output(self):
names = {i: self.classes[i] for i in range(len(self.classes))} # 标签类别
data = {
'path': os.path.join(os.getcwd(), self.args.target),
'train': "train/images",
'val': "val/images",
'test': "test/images",
'names': names
# 'nc': len(self.classes)
}
with open(os.path.join(self.args.target, 'data.yaml'), 'w', encoding="utf-8") as file:
yaml.dump(data, file, allow_unicode=True)
def report(self):
tables = [["标签", "数量"]]
for label, files in self.lables.items():
if len(files) == 0:
continue
tables.append([label, len(files)])
table = Texttable(max_width=160)
table.add_rows(tables)
print(table.draw())
for file in self.missed:
self.logger.warning(f"丢失文件 {file}")
def main(self):
if self.args.source and self.args.target:
self.logger.info("Start")
self.input()
self.process()
self.output()
self.report()
self.logger.info("Done")
else:
self.parser.print_help()
exit()
if __name__ == "__main__":
try:
run = LabelimgToYolo()
run.main()
except KeyboardInterrupt as e:
print(e)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
##############################################
# Home : https://www.netkiller.cn
# Author: Neo <netkiller@msn.com>
# Upgrade: 2025-01-07
##############################################
import glob
import hashlib
from texttable import Texttable
try:
import uuid,shutil,yaml,cv2
import os,sys,random,argparse
from tqdm import tqdm
from PIL import Image, ImageOps
from ultralytics import YOLO
except ImportError as err:
print("Import Error: %s" % (err))
exit()
class YoloLabelRemove():
count = 0
def __init__(self):
self.basedir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(self.basedir)
self.parser = argparse.ArgumentParser(description='YOLO标签删除工具')
self.parser.add_argument('--source', type=str, default=None, help='左侧目录',metavar="/tmp/dir1")
self.parser.add_argument('--label', type=int, default=-1, help='长边尺寸',metavar=0)
self.parser.add_argument('--output', type=str, default=None, help='输出目录', metavar="/tmp/output")
self.parser.add_argument('--clean', action="store_true", default=False, help='清理之前的数据')
self.args = self.parser.parse_args()
def scanfile(self,path):
files = []
files = glob.glob(path)
return (files)
def scandir(self,path):
files = []
for name in os.listdir(path):
if os.path.isdir(os.path.join(path, name)):
files.append(name)
return (files)
def input(self):
try:
if self.args.clean:
if os.path.exists(self.args.output):
shutil.rmtree(self.args.output)
os.makedirs(self.args.output,exist_ok=True)
self.files = self.scanfile(os.path.join(self.args.source,"*.txt"))
# print(self.files)
except Exception as e:
# log.error(e)
print("input: ", e)
exit()
def process(self):
with tqdm(total=len(self.files), ncols=100) as progress:
for file in self.files:
progress.set_description(file)
filename = os.path.basename(file)
try:
if filename.lower() == 'classes.txt':
continue
else:
# print(file)
output = os.path.join(self.args.output, filename)
with open(file, "r") as original, open(output, "w") as file:
for line in original.readlines():
# print(line)
if line.startswith(f"{self.args.label} "):
self.count += 1
continue
file.write(line)
# print(f"txt1={txt1}, txt2={txt2}")
except FileNotFoundError as e:
print(str(e))
exit()
progress.update(1)
def output(self):
tables = [["输出","处理"]]
tables.append([len(self.files),self.count])
table = Texttable(max_width=100)
table.add_rows(tables)
print(table.draw())
pass
def main(self):
print(self.args)
if self.args.source and self.args.output:
self.input()
self.process()
self.output()
else:
self.parser.print_help()
exit()
if __name__ == "__main__":
try:
run = YoloLabelRemove()
run.main()
except KeyboardInterrupt as e:
print(e)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
##############################################
# Home : https://www.netkiller.cn
# Author: Neo <netkiller@msn.com>
# Upgrade: 2024-11-00
##############################################
try:
import uuid
import shutil
import os,sys,random,argparse
import yaml
import json
from PIL import Image
from ultralytics import YOLO
except ImportError as err:
print("Import Error: %s" % (err))
exit()
class Dataset:
def __init__(self):
self.data = {}
def __str__(self):
return (f"classes={self.classes} data={len(self.data)} train={len(self.train)} val={len(self.val)} test={len(self.test)}")
class Classify():
# background = (22, 255, 39) # 绿幕RGB模式(R22 - G255 - B39),CMYK模式(C62 - M0 - Y100 - K0)
background = (0, 0,0)
def __init__(self):
self.basedir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(self.basedir)
# print(basedir)
# exit()
self.parser = argparse.ArgumentParser(description='YOLO 图像分类数据处理')
self.parser.add_argument('--source', type=str, default=None, help='图片来源地址')
self.parser.add_argument('--target', default=None, type=str, help='图片目标地址')
self.parser.add_argument('--test', type=int, default=10, help='测试数量',metavar=100)
self.parser.add_argument('--clean', action="store_true", default=False, help='清理之前的数据')
self.parser.add_argument('--crop', action="store_true", default=False, help='裁剪')
self.parser.add_argument('--uuid', action="store_true", default=False, help='重命名图片为UUID')
self.args = self.parser.parse_args()
def mkdirs(self,path):
if not os.path.exists(path):
os.makedirs(path)
def scanfile(self,path):
files = []
for name in os.listdir(path):
if os.path.isfile(os.path.join(path, name)):
files.append(name)
return (files)
def scandir(self,path):
files = []
for name in os.listdir(path):
if os.path.isdir(os.path.join(path, name)):
files.append(name)
return (files)
def walkdir(self,path):
for dirpath, dirnames, filenames in os.walk(path):
print(f"dirpath={dirpath}, dirnames={dirnames}, filenames={filenames}")
# print(filenames)
def crop(self,source,target):
boxes = self.annotation(source)
if boxes is not None:
xyxy = boxes.xyxy[0]
xywh = boxes.xywh[0]
original = Image.open(source)
# width, height = original.size
# x0, y0, x1, y1 = map(int, results[0].boxes[0].xyxy[0])
tongue = original.crop(tuple(map(int, xyxy)))
# crop.save(output)
width, height = tongue.size
width += 50
height += 50
image = Image.new('RGB', (width, height), self.background)
image.paste(tongue, (
int(width / 2) - int(tongue.size[0] / 2), int(height / 2) - int(tongue.size[1] / 2)))
image.save(target)
def source(self,label,filename):
return os.path.join(self.args.source, label, filename)
def target(self,mode, label,filename):
if self.args.uuid:
extension = os.path.splitext(filename)[1]
path = os.path.join(self.args.target,f"{mode}", label,f"{uuid.uuid4()}{extension}")
else:
path = os.path.join(self.args.target,f"{mode}",label, filename)
return path
def images(self):
for label, files in self.dataset.data.items():
for name in files:
try:
# print(name)
source = self.source(label,name)
# print(input)
target = self.target('train',label,name)
# print(target)
# self.dataset.train[label].append(target)
if self.args.crop:
self.crop(source,target)
else:
# print(f"COPY train source={source}, target={target}")
shutil.copyfile(source, target)
except Exception as e:
# log.error(e)
print("train: ", e)
exit()
def test(self):
for label, files in self.dataset.data.items():
if len(files) < self.args.test:
self.args.test = len(files)
vals = random.sample(files, self.args.test)
# self.dataset.val[label] = []
for name in vals:
try:
source = self.source(label, name)
# print(input)
target = self.target('test',label,name)
# print(target)
# self.dataset.val[label].append(target)
if self.args.crop:
self.crop(source, target)
else:
# print(f"COPY val source={source}, target={target}")
shutil.copyfile(source, target)
# shutil.copyfile(os.path.join(self.args.source, label,name), os.path.join(self.args.target, 'val/images',name))
except Exception as e:
# log.error(e)
print("test: ", e)
exit()
def annotation(self,source):
if not os.path.exists(path):
return None
try:
results = self.model(source, verbose=False)
if len(results):
# print(results[0])
if len(results[0].boxes):
# print(results[0].boxes)
# if len(results[0].boxes[0].xyxy):
# print(results[0].boxes[0].xyxy[0])
# # log.info(f"Image filename={filename}")
# print(results[0].boxes[0].xywhn[0])
# return results[0].boxes[0].xywhn[0]
return results[0].boxes[0]
except Exception as e:
# log.error(e)
print("annotation: ",e)
exit()
return None
def input(self):
self.dataset = Dataset()
self.mkdirs(os.path.join(self.args.target))
directory = [
'train', 'test'
]
self.dataset.data = {}
for cls in self.scandir(os.path.join(self.args.source)):
self.dataset.data[cls] = self.scanfile(os.path.join(self.args.source, cls))
for dir in directory:
self.mkdirs(os.path.join(self.args.target, dir,cls))
# print(self.dataset)
# exit()
pass
def process(self):
self.images()
self.test()
pass
def output(self):
pass
def main(self):
# print(self.args)
if self.args.clean:
if os.path.exists(self.args.target):
shutil.rmtree(self.args.target)
if self.args.source and self.args.target:
self.model= YOLO(f"{self.basedir}/model/Tongue/weights/best.pt"),
self.input()
self.process()
self.output()
else:
self.parser.print_help()
exit()
if __name__ == "__main__":
try:
run = Classify()
run.main()
except KeyboardInterrupt as e:
print(e)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
##############################################
# Home : https://www.netkiller.cn
# Author: Neo <netkiller@msn.com>
# Upgrade: 2024-12-23
##############################################
try:
import os,sys,random,argparse,uuid
import shutil,yaml,json
import cv2
from tqdm import tqdm
from ultralytics import YOLO
from texttable import Texttable
except ImportError as err:
print("Import Error: %s" % (err))
exit()
class Dataset:
def __init__(self):
self.data = {}
def __str__(self):
return (f"classes={self.classes} data={len(self.data)} train={len(self.train)} val={len(self.val)} test={len(self.test)}")
class Classify():
# background = (22, 255, 39) # 绿幕RGB模式(R22 - G255 - B39),CMYK模式(C62 - M0 - Y100 - K0)
background = (0, 0,0)
checklists = []
def __init__(self):
self.basedir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(self.basedir)
# print(basedir)
# exit()
self.parser = argparse.ArgumentParser(description='YOLO 图像分类数据处理')
self.parser.add_argument('--source', type=str, default=None, help='图片来源地址')
self.parser.add_argument('--target', default=None, type=str, help='图片目标地址')
self.parser.add_argument('--output', type=str, default=None, help='输出识别图像', metavar="")
self.parser.add_argument('--checklist', type=str, default=None, help='输出识别图像', metavar="")
self.parser.add_argument('--test', type=int, default=10, help='测试数量',metavar=100)
self.parser.add_argument('--clean', action="store_true", default=False, help='清理之前的数据')
self.parser.add_argument('--crop', action="store_true", default=False, help='裁剪')
self.parser.add_argument('--uuid', action="store_true", default=False, help='重命名图片为UUID')
self.parser.add_argument('--verbose', action="store_true", default=False, help='过程输出')
self.args = self.parser.parse_args()
def mkdirs(self,path):
if not os.path.exists(path):
os.makedirs(path)
def scanfile(self,path):
files = []
for name in os.listdir(path):
if os.path.isfile(os.path.join(path, name)):
files.append(name)
return (files)
def scandir(self,path):
files = []
for name in os.listdir(path):
if os.path.isdir(os.path.join(path, name)):
files.append(name)
return (files)
def walkdir(self,path):
for dirpath, dirnames, filenames in os.walk(path):
print(f"dirpath={dirpath}, dirnames={dirnames}, filenames={filenames}")
# print(filenames)
def boxes(self, source:str,target:str)->None:
if not os.path.exists(source):
return None
results = self.model(source, verbose=self.args.verbose)
image = cv2.imread(source)
filename, extension = os.path.splitext(os.path.basename(target))
for result in results:
# print(result)
if self.args.output:
result.save(filename=os.path.join(self.args.output, os.path.basename(source)))
try:
boxes = result.boxes.data.cpu().numpy() # YOLO 边界框格式:[x1, y1, x2, y2, confidence, class]
# # print(result.boxes.data.tolist())
for idx, box in enumerate(boxes):
x1, y1, x2, y2, conf, cls = map(int, box[:6])
cropped = image[y1:y2, x1:x2]
output = os.path.join(os.path.dirname(target), f"{filename}_{idx}{extension}")
cv2.imwrite(output, cropped)
# print(f"Saved cropped image: {output}")
if len(boxes) > 1:
self.checklists.append(target)
if self.args.checklist:
result.save_crop(save_dir=os.path.join(self.args.checklist, 'crop'), file_name=filename)
result.save(filename=os.path.join(self.args.checklist, os.path.basename(source)))
# print(boxes)
except Exception as e:
# log.error(e)
print("boxes: ",e)
exit()
def source(self,label,filename):
return os.path.join(self.args.source, label, filename)
def target(self,mode, label,filename):
if self.args.uuid:
extension = os.path.splitext(filename)[1]
path = os.path.join(self.args.target,f"{mode}", label,f"{uuid.uuid4()}{extension}")
else:
path = os.path.join(self.args.target,f"{mode}",label, filename)
return path
def train(self):
for label, files in self.dataset.data.items():
with tqdm(total=len(files), ncols=100) as progress:
progress.set_description(f"train/{label}")
for name in files:
try:
# print(name)
source = self.source(label,name)
# print(input)
target = self.target('train',label,name)
# print(target)
if self.args.crop:
# self.crop(source,target)
self.boxes(source, target)
else:
# print(f"COPY train source={source}, target={target}")
shutil.copyfile(source, target)
except Exception as e:
# log.error(e)
print("train: ", e)
exit()
progress.update(1)
def test(self):
for label, files in self.dataset.data.items():
if len(files) < self.args.test:
self.args.test = len(files)
vals = random.sample(files, self.args.test)
with tqdm(total=len(vals), ncols=100) as progress:
progress.set_description(f"test/{label}")
for name in vals:
try:
source = self.source(label, name)
# print(input)
target = self.target('test',label,name)
# print(target)
if self.args.crop:
self.boxes(source, target)
else:
# print(f"COPY val source={source}, target={target}")
shutil.copyfile(source, target)
except Exception as e:
# log.error(e)
print("test: ", e)
exit()
progress.update(1)
def val(self):
for label, files in self.dataset.data.items():
if len(files) < self.args.test:
self.args.test = len(files)
vals = random.sample(files, self.args.test)
with tqdm(total=len(vals), ncols=100) as progress:
progress.set_description(f"val/{label}")
for name in vals:
try:
source = self.source(label, name)
# print(input)
target = self.target('val',label,name)
# print(target)
if self.args.crop:
self.boxes(source, target)
else:
# print(f"COPY val source={source}, target={target}")
shutil.copyfile(source, target)
except Exception as e:
# log.error(e)
print("test: ", e)
exit()
progress.update(1)
def input(self):
if self.args.clean:
if os.path.exists(self.args.target):
shutil.rmtree(self.args.target)
if os.path.exists(self.args.output):
shutil.rmtree(self.args.output)
if os.path.exists(self.args.checklist):
shutil.rmtree(self.args.checklist)
self.dataset = Dataset()
self.mkdirs(os.path.join(self.args.target))
self.mkdirs(os.path.join(self.args.output))
if self.args.checklist:
self.mkdirs(os.path.join(self.args.checklist))
directory = [
'train', 'test','val'
]
self.dataset.data = {}
for cls in self.scandir(os.path.join(self.args.source)):
self.dataset.data[cls] = self.scanfile(os.path.join(self.args.source, cls))
for dir in directory:
self.mkdirs(os.path.join(self.args.target, dir,cls))
# print(self.dataset)
self.model = YOLO(f"{self.basedir}/model/Tongue/weights/best.pt")
pass
def process(self):
self.train()
self.test()
self.val()
pass
def output(self):
# for checklist in self.checklists:
# print(checklist)
tables = [["检查列表"]]
for file in self.checklists:
tables.append([file])
table = Texttable(max_width=100)
table.add_rows(tables)
print(table.draw())
pass
def main(self):
if self.args.source and self.args.target:
self.input()
self.process()
self.output()
else:
self.parser.print_help()
exit()
if __name__ == "__main__":
try:
run = Classify()
run.main()
except KeyboardInterrupt as e:
print(e)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
##############################################
# Home : https://www.netkiller.cn
# Author: Neo <netkiller@msn.com>
# Upgrade: 2024-12-23
##############################################
import glob
import os
from tqdm import tqdm
from texttable import Texttable
from ultralytics import YOLO
class ClassifyTest:
def __init__(self, input: str, output: str):
self.input = input
self.output = output
self.tables = [["分类", "数量", "正确", "正确率", "损失"]]
# model = YOLO('../model/Tongue/weights/best.pt')
self.model = YOLO("../model/Classify/weights/best.pt")
self.loss = []
pass
def scanfile(self, path):
files = []
for name in os.listdir(path):
if os.path.isfile(os.path.join(path, name)):
files.append(name)
return (files)
def scandir(self, path):
files = []
for name in os.listdir(path):
if os.path.isdir(os.path.join(path, name)):
files.append(name)
return (files)
def makedirs(self, path):
if not os.path.exists(path):
os.makedirs(path)
def predict(self, classification):
images = glob.glob('*.jpg', root_dir=os.path.join(self.input, classification))
total = len(images)
count = 0
with tqdm(total=total, ncols=100) as progress:
progress.set_description("%s" % classification)
for image in images:
# print(image)
source = os.path.join(self.input, classification, image)
results = self.model.predict(source, verbose=False)
for result in results:
result.save(os.path.join(self.output, image))
if len(result.probs.data) >= 1:
count += 1
else:
self.loss.append(source)
progress.update(1)
self.tables.append([classification, total, count, f"{int(count / total * 100)}%", len(self.loss)])
def report(self):
table = Texttable(max_width=160)
table.add_rows(self.tables)
print(table.draw())
for f in self.loss:
print(f)
def main(self):
self.makedirs(self.output)
for dir in self.scandir(input):
self.predict(dir)
self.report()
if __name__ == "__main__":
try:
input = r'E:/classify'
output = r'E:/tmp/classify'
classify = ClassifyTest(input, output)
classify.main()
except KeyboardInterrupt as e:
print(e)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
##############################################
# Home : https://www.netkiller.cn
# Author: Neo <netkiller@msn.com>
# Upgrade: 2024-12-31
##############################################
import glob
import hashlib
from texttable import Texttable
try:
import uuid,shutil,yaml,cv2
import os,sys,random,argparse
from tqdm import tqdm
from PIL import Image, ImageOps
from ultralytics import YOLO
except ImportError as err:
print("Import Error: %s" % (err))
exit()
class YoloMerge():
lose = []
def __init__(self):
self.basedir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(self.basedir)
# print(basedir)
self.parser = argparse.ArgumentParser(description='合并YOLO标签工具')
self.parser.add_argument('--left', type=str, default=None, help='左侧目录',metavar="/tmp/dir1")
self.parser.add_argument('--right', default=None, type=str, help='右侧目录',metavar="/tmp/dir2")
# self.parser.add_argument('--imgsz', type=int, default=640, help='长边尺寸',metavar=640)
self.parser.add_argument('--output', type=str, default=None, help='最终输出目录', metavar="/tmp/output")
self.parser.add_argument('--clean', action="store_true", default=False, help='清理之前的数据')
# self.parser.add_argument('--md5sum', action="store_true", default=False, help='使用md5作为文件名')
# self.parser.add_argument('--uuid', action="store_true", default=False, help='重命名图片为UUID')
# self.parser.add_argument('--crop', action="store_true", default=False, help='裁剪')
self.args = self.parser.parse_args()
def scanfile(self,path):
files = []
# for name in os.listdir(path):
# if os.path.isfile(os.path.join(path, name)):
# files.append(name)
files = glob.glob(path)
return (files)
def scandir(self,path):
files = []
for name in os.listdir(path):
if os.path.isdir(os.path.join(path, name)):
files.append(name)
return (files)
def input(self):
try:
if self.args.clean:
if os.path.exists(self.args.output):
shutil.rmtree(self.args.output)
os.makedirs(self.args.output,exist_ok=True)
self.lefts = self.scanfile(os.path.join(self.args.left,"*.txt"))
self.rights = self.scanfile(os.path.join(self.args.right, "*.txt"))
# print(self.files)
except Exception as e:
# log.error(e)
print("input: ", e)
exit()
def process(self):
with tqdm(total=len(self.lefts), ncols=100) as progress:
for file in self.lefts:
progress.set_description(file)
filename = os.path.basename(file)
try:
if filename.lower() == 'classes.txt':
shutil.copyfile(file, os.path.join(self.args.output,filename))
else:
left = os.path.join(self.args.left, filename)
right = os.path.join(self.args.right, filename.replace('_0.','.'))
output = os.path.join(self.args.output, filename)
image = filename.replace('.txt','.jpg')
# print(f"left={left}, right={right}, output={output}")
shutil.copyfile(os.path.join(self.args.left, image), os.path.join(self.args.output, image))
if not os.path.isfile(right):
shutil.copyfile(left, output)
# print(f"test={os.path.isdir(right)} right={right}")
else:
with open(left, "r") as file1, open(right, "r") as file2, open(output, "w") as file:
txt1 = file1.read()
txt2 = file2.read()
file.write(txt1)
file.write(txt2)
# print(f"txt1={txt1}, txt2={txt2}")
except FileNotFoundError as e:
print(str(e))
self.lose.append(e.filename)
exit()
progress.update(1)
def output(self):
if not self.lose:
return
tables = [["丢失文件"]]
for file in self.lose:
tables.append([file])
tables.append([f"合计:{len(self.lose)}"])
table = Texttable(max_width=100)
table.add_rows(tables)
print(table.draw())
pass
def main(self):
# print(self.args)
if self.args.left and self.args.right:
if self.args.left == self.args.right:
print("目标文件夹不能与原始图片文件夹相同")
self.input()
self.process()
self.output()
else:
self.parser.print_help()
exit()
if __name__ == "__main__":
try:
run = YoloMerge()
run.main()
except KeyboardInterrupt as e:
print(e)